
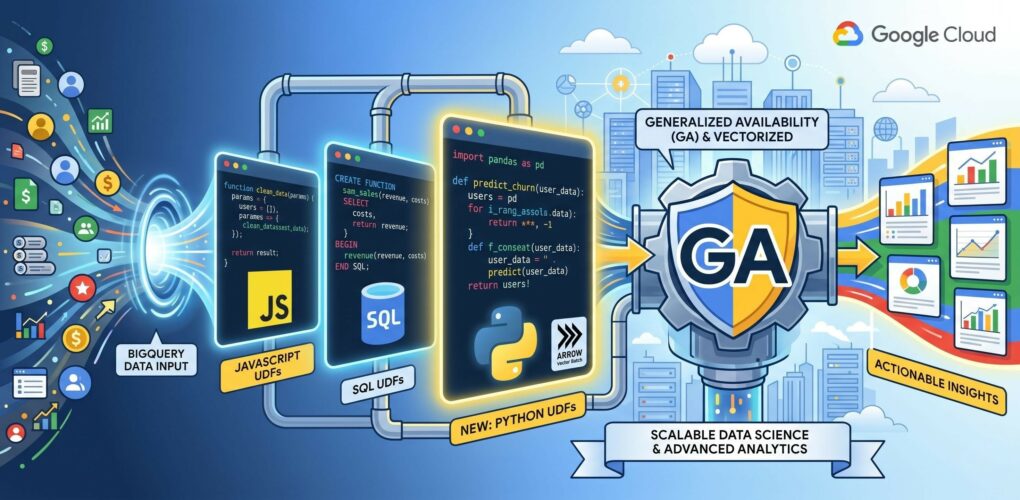
Google BigQuery a anunțat în urmă cu câteva zile extinderea funcțiilor definite de utilizator (User-Defined Functions – UDFs).
Dacă ai lucrat cu datele din Google Analytics 4 în BigQuery, probabil că ai scris de foarte multe ori comanda UNNEST. Acest lucru se poate schimba datorită user-defined functions. Tot prin UDFs putem curăța URL-urile din GA4, precum și modifica Channel Grouping, calcula sesiunile active sau a duratei reale a sesiunii.
În caz că sună cunoscut, anul trecut am scris și despre apariția UDFs în limbajul DAX pentru Microsoft PowerBI, Excel și SSAS. Revenind la GoogleBigQuery, acesta a anunțat că le suportă încă din august 2015, dar atunci puteau fi scrise doar în JavaScript.
Din 2016, BigQuery a permis scrierea acestora direct în SQL (se pot crea prin comanda CREATE FUNCTION). În anul 2020 au lansat Authorized UDFs, care permite unui analist să creeze o funcție care interoghează o tabelă securizată, la care el poate să nu aibă acces.
Revenind la știrile din această lună, Google a anunțat suport nativ pentru Python în UDFs și câteva optimizări masive de infrastructură la conferința Google Cloud Next din aprilie 2026 și în actualizările anunțate oficial la finalul lunii mai 2026, pe care le voi detalia în continuare.
Lansarea Python UDFs
Cea mai mare actualizare adusă la funcțiile definite de utilziator din BigQuery este posibilitatea de a scrie UDF-uri direct în Python, rulând codul într-un mediu securizat tip container. Utilizatorii nu mai sunt limitați la SQL și JavaScript dacă vor să își definească propriile funcții în BigQuery.
Astfel, utilziatorii pot importa pachete populare de Data Science și analiză precum pandas, numpy, scipy sau scikit-learn direct în funcție, folosind opțiunea packages.
UDF-uri Vectorizate cu Apache Arrow
Odată cu introducerea Python-ului, o mare problemă era viteza de procesare (overhead-ul creat prin trimiterea rând cu rând a datelor către containerul de Python).
Google a rezolvat asta în mai 2026 prin lansarea UDF-urilor Vectorizate, care folosesc interfața Apache Arrow RecordBatch.
Astfel, în loc ca BigQuery să trimită datele linie cu linie către funcția ta, le trimite în pachete masive (batches) direct sub formă de pandas.DataFrame.
Rezultatul este o performanță de zeci de ori mai rapidă pentru calcule matematice complexe, simulări financiare sau transformări masive de text.
Monitorizare prin Cloud Monitoring și Controlul Concurenței
Pentru inginerii de date care rulează mii de astfel de funcții la nivelul enterprise, Google a adăugat funcționalități esențiale de DevOps pentru UDF-uri:
- Integrare cu Cloud Monitoring – UDF-urile exportă acum automat metrici operaționale. Utilizatorii pot vedea exact cât CPU și câtă memorie (RAM) consumă funcțiile customizate;
- Concurrency Control – a fost introdus parametrul
container_request_concurrencyîn statement-ulCREATE FUNCTION. Acesta permite limitarea numărului de cereri simultane pe care le poate procesa o singură instanță de container, oferindu-ți un control strict asupra resurselor pentru a evita erorile de tip Out of Memory.
Ultimul tren pentru UDF-urile din Legacy SQL
Tot în mai 2026, Google a emis o avertizare finală privind Legacy SQL. Începând cu 1 iunie 2026, accesul la vechiul dialect Legacy SQL (și implicit la UDF-urile scrise în formatul vechi din 2015) va fi complet blocat pentru proiectele care nu le-au mai folosit în ultimele luni.
Google forțează astfel migrarea completă către Standard SQL (GoogleSQL) pentru o securitate și performanță sporită. Pe scurt, dacă înainte UDF-urile din BigQuery erau doar pentru mici scripturi de curățat text în JavaScript, update-ul din mai 2026 le-a transformat în instrumente veritabile de Data Science și Machine Learning în-situ, eliminând nevoia de a mai exporta datele din BigQuery în notebook-uri externe pentru calcule complexe.
BigQuery a anunțat câteva funcționalități majore privind user-defined functions și sunt tare curios cum vor fi acestea utilizate de către utilizatori.