
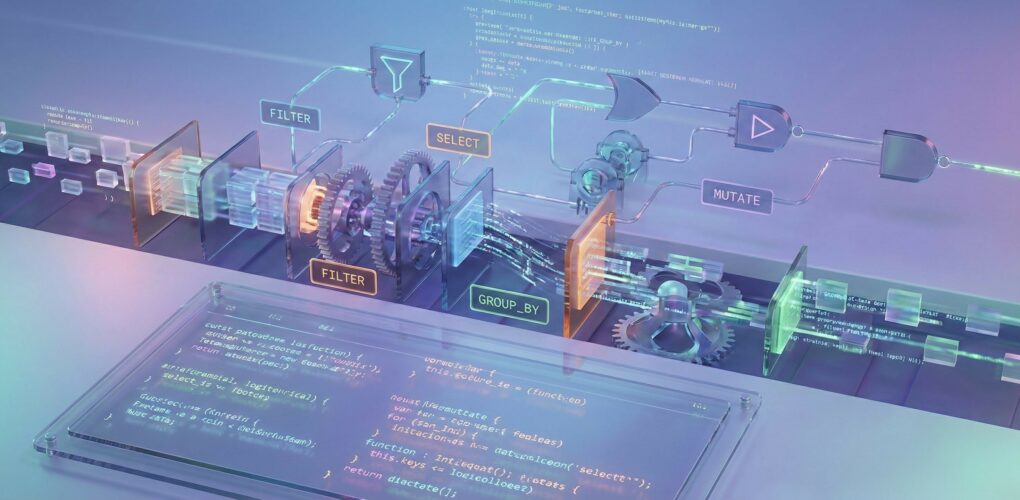
dplyr este unul dintre cele mai populare pachete din limbajul de programare R, fiind considerat „cuțitul elvețian” pentru manipularea și transformarea datelor. Acesta face parte din ecosistemul tidyverse și a fost creat special pentru a face procesul de curățare și explorare a datelor mai rapid, mai intuitiv și mai ușor de citit.
Luna aceasta a aprărut o nouă versiune majoră de dplyr. Versiunea 1.2.0 se concentrează pe o viteză ridicată, precum și pe simplificarea sintaxei și eliminarea pașilor redundanți.
Despre universul tidyverse am scris și în trecut, în special despre ggplot2, pachetul pentru gramatica graficelor. În schimb, dplyr este pachetul care se ocupă de gramatica manipulării datelor.
Scurt istoric
dplyr a apărut în ianuarie 2014, fiind conceput ca un succesor mai rapid și mai coerent pentru pachetul plyr. Pentru a lucra eficient cu datele, dplyr se bazează pe câteva funcții cheie care acoperă majoritatea nevoilor de procesare:
filter()– selectează rânduri pe baza unor condițiiselect()– selectează coloane specificemutate()– creează coloane noi sau le modifică pe cele existentearrange()– sortează rândurilesummarize()– oferă un rând de statistici privind tabelul
Între 2015 și 2019, acest pachet devine parte centrală din tidyverse și este adoptată complet filozofia tidy data.
În 2020 a apărut dplyr 1.0.0. Se spune că este versiunea care marchează trecerea la „dplyr modern”, și vine cu funcții precum:
across()– transformă mai multe coloane de-odată, fără a repeta codulif_any()șiif_all()– scanează rândurile pentru a vedea unde este îndeplinită regularowwise()este modernizat; dacă R face calcule pe coloană, aceast funcție îl face să privească tabelul rând cu rândsummarize()devine mai flexibil și poate oferi mai mult decât o valoare pentru fiecare grup
În 2022 a apărut dplyr 1.1.0, care a adus prima dată argumentul .by(), acesta grupând temporar datele, precum și reframe(), care a preluat de la summarize() rezultatele care înseamnă mai mult de un rând per grup.
Atât argumentul .by(), cât și funcția reframe() au devenit stabile în versiunea lansată în februarie 2026.
Extinderea familiei filter()
Înapoi la versiunea 1.2.0, avem mari schimbări la nivelul filtrării datelor. Așa cum scriam mai sus, filter() este una dintre principalele funcții ale dplyr. Este optimizată pentru păstrarea sau includerea datelor, însă era folosită deseori și pentru excluderea de date.
În acest sens, noua versiune aduce o nouă funcție, filter_out(), care va face excluderea mai rapidă.
Așa cum spuneam, argumentul .by a devenit stabil, astfel că acum putem vedea datele grupate chiar din filter(), împreună cu acest argument. Spre comparație, înainte de acest argument, trebuia să grupăm datele, să le filtrăm, după care să le degrupăm.
Combinații cu when_any() și when_all()
Acestea sunt funcții ajutătoare (helpers) menite să simplifice logica booleană (ȘI / SAU) atunci când ai multe condiții.
Condițiile vor fi introduse ca argumente ale acestor funcții, cu virgulă între acestea.
Acesea sunt funcții asemănătoare cu if_any() / if_all(), care se folosesc la operațiuni pe coloane, în timp ce when_any() / when_all() se folosesc pentru a combina expresii logice diferite.
Aceste funcșii ajutătoare vin ca un ajutor la filter_out(), pentru că le putem utiliza împreună.
Crearea de noi coloane
Încă din versiunea 0.5.0 avem la dispoziție case_when(), care salvează utilizatorii de șirurile de ifelse(). În ultima versiune, aceasta a fost rescrisă aproape integral în C++, fâcând execuția cu până la 40% mai rapidă față de versiunea 1.1.0.
Tot în ultima versiune, funția case_when() a fost completată cu:
recode_values()– creează coloane prin înlocuiri simple, de tipul „cheie-valoare”replaces_when()– nu creează coloane noi, dar poate înlocui anumite valori; păstrează valorile originale și le schimbă doar pe cele care îndeplinesc condiția, fiind mult mai eficient din punct de vedere al memorieireplace_values()– pentru pentru a înlocui valori, dar fără să mai punem condiții multiple încase_when()

Așa cum se poate observa, lucrul cu date în dplyr devine mai simplu odată cu ultima versiune. Mă bucur să văd că există preocupare și principalele pachete pentru date din R sunt actualizate constant.